重新想像非結構化資料 ETL
February 14, 2025
生成式 AI 正在改變軟體,那它又會如何改變我們使用文件、圖片和影片等非結構化資料的方式呢?
試著想像一下,一種能夠理解任何物理信號,並且有智慧地回應任何人類語言指令的電腦系統。
本文分享了我過去三年在快速發展的 AI 和資料領域中的經驗,詳述了我們在 Instill AI 打造非結構化資料 ETL 平台和 AI 產品的旅程。我們迭代了好幾次產品設計,從一開始為 AI 建構者提供的無程式碼工具,轉變為低程式碼工具,如今再度轉為面向所有 AI 使用者且基於對話介面的 UI/UX 產品。
隨著 AI 基礎模型的不斷進步,它們已經改變了軟體開發實踐,從傳統的命令式程式編輯到提示工程,從思維鏈(CoT)和 ReAct 等框架,到如今能使系統更加獨立自主的 agentic workflows。但這一趨勢是否會繼續改變包括現代資料堆棧(Modern Data Stack,MDS)在內的各個軟體工程領域的最佳實踐方法呢?也許在看完本文後,你會得出與我相同的結論。
注意:在深入本文前,你可能需要熟悉本文中使用的術語,請參閱詞彙表。
生成式 AI = 新的軟體推動器
我的學術背景是電腦視覺(CV,Computer Vision)和機器學習(Machine Learning,ML),一路上見證了這些領域從傳統的 CV 算法,如方向梯度直方圖(Histogram of Oriented Gradients,HoG)和尺度不變特徵變換(Scale-Invariant Feature Transform,SIFT),到經典的 ML 方法如支持向量機(Support Vector Machine,SVM)、隨機森林(Random Forest,RF)和 AdaBoost,再到今天(幾乎)可以解決所有不適定問題(ill-posed problems)的端到端深度學習(End-to-End Deep Learning,DL)基礎模型。
最讓我印象深刻的不是這些基礎模型有多強大,而是它們在軟體工具中的顛覆性。我們看到 OpenAI Research 可以將外部網絡搜索整合進 agentic workflows 中,對某個主題進行深入研究,OpenAI-o1 和 DeepSeek-R1 在推理過程中進行自我反思以提高推理和答案的準確性,OpenAI Operator 和 Anthropic Computer Use 通過控制用戶的鍵盤和鼠標執行機器人流程自動化(RPA,Robotic Process Automation)任務。
自 2012 年以來,第一次 DL 熱潮圍繞卷積神經網絡(ConvNets)及其在 CV 中的 ImageNet 資料集的突破。(當時,這其實已經是第三次 AI 熱潮,緊隨 Symbolic AI 時代之後。)然而,ConvNets 卻沒有迎來它的大爆發,主要是因爲它們依賴於監督式學習(Supervised Learning),其需要大量標註資料。此外,由於圖片和影片內容的高動態性和不可預測性,預訓練的 ConvNets 模型並無法很好地被泛化。
然而,在 2017 年,轉換器(Transformers)出現了,徹底改變了遊戲規則。它們從自然語言處理(Natrual Language Processing,NLP)中脫穎而出,消除了對標註資料的需求,這主要歸功於它們所採用的自回歸自監督學習架構(Autoregressive Self-Supervised Learning)。由於人類語言本身就有一定的泛化能力,基於轉換器的基礎模型不僅在文字任務中非常有效,而且在不同模態(如文字到圖片,或是圖片到文字)中也表現出色。如今,我們將這整個領域稱為生成式 AI,涵蓋所有 AI 驅動的內容生成任務。
到了 2022 年 11 月,隨著 GPT-2(2019 年的 1.5B 參數模型)和 GPT-3(2020 年的 175B 參數模型)的成功,GPT-3.5(針對基於聊天的互動進行了優化)標誌著 ChatGPT 的誕生。GPT 系列的成功很大程度上歸功於規模定律,而不是任何不可告人的”秘方”。基於這點,任何擁有足夠 GPU 計算能力的單位,理論上都可以複製類似的結果,儘管這並不容易,但實際上絕對可行。
從那時起,我們見證了基礎模型的全球競爭。最初,競爭集中在美國和歐盟,Anthropic、Cohere、Mistral 和 Google 是主要參與者。現在,中國的 AI 公司如 DeepSeek 和 MiniMax 也加入了競爭,提供了 30 倍便宜的基礎模型 API 價格。產業趨勢很明顯:基礎模型正在迅速商品化,正在快速轉變為軟體平台和應用程序可以從中受益的基礎設施。
MDS 的現狀
從 2010 年到 2024 年初,相比於 AI 領域的突飛猛進,MDS 幾乎沒有多大進展。即便如此,如今 AI 對 Data 領域的影響,已變得不可避免,種種跡象已經開始顯現:
- Databricks 的 J 輪融資,籌集了 100 億美元,公司估值達到 620 億美元,將投資於新的 AI 產品。
- Snowflake 收購了 DataVolo,因為其非結構化資料串流能力。
- DataStax 收購了 Langflow,因為其無程式碼 AI 工作流構建器。
而這僅僅是開始。AI 的產業革命不僅在改變軟體開發,它正在重新定義整個資料生態系統。這其中最令人興奮的部分是?我們有機會塑造它!
曲折的旅程
Instill AI 如何在如此變動的大環境下適應和應變呢?我們一直不斷在反思,如何最有效率地實現我們的最終目標,也就是讓每個人都能輕易使用 AI。我們公司的使命是賦與人們自動化日常任務的能力,提高個人生產力,並從繁瑣、重複的瑣事中解放出來。
作為一家早期新創公司,我們最大的挑戰是實現產品市場契合度(product-market fit, PMF),這是一個持續的、迭代的過程,而不是一次性的里程碑。為了能讓公司生存下去,我們總是必須在「創新」和「產品可行性」之間謹慎平衡。雖然人工通用智能(Artificial General Intelligence,AGI)看起來可能是最終所有問題的解決方案,但我們相信僅靠它是無法實現我們的目標的。此外,儘管我們公司的強項是技術,但我們並沒有可以讓我們搞研究和訓練基礎模型的資金。所以,我們採取了一種更務實的路徑,根據軟體工具必須與 AI 一同發展的事實,我們不僅僅關注 AI 基礎模型的發展,也優先考慮資料的配套工具,因為我們深刻理解到,僅靠 AI 模型是無法完善整條 AI 價值鏈的。
一步式非結構化資料 ETL(2022年)
基於這樣的想法,我們最初確定了我們的目標受眾為資料工程師、資料科學家、AI 工程師和 AI 研究人員,這些需要構建非結構化資料 ETL 管道的 AI 建構者。
受到 dbt(主要是處理 ETL 中的 “T”)和 Airbyte(主要是 ELT 中的 “EL” 資料遷移)的啟發,我們最初構建了一個系統,將資料源和目的地與單個 DL 模型(無論是 LLM、STT/TTS 模型還是物件檢測模型)連接起來(見圖 1)。這是我們的第一個最小可行性產品(Minimum Viable Product,MVP),主要是用來展示如何在 ETL 框架中處理非結構化資料的概念,好讓我們可以進行種子輪融資。
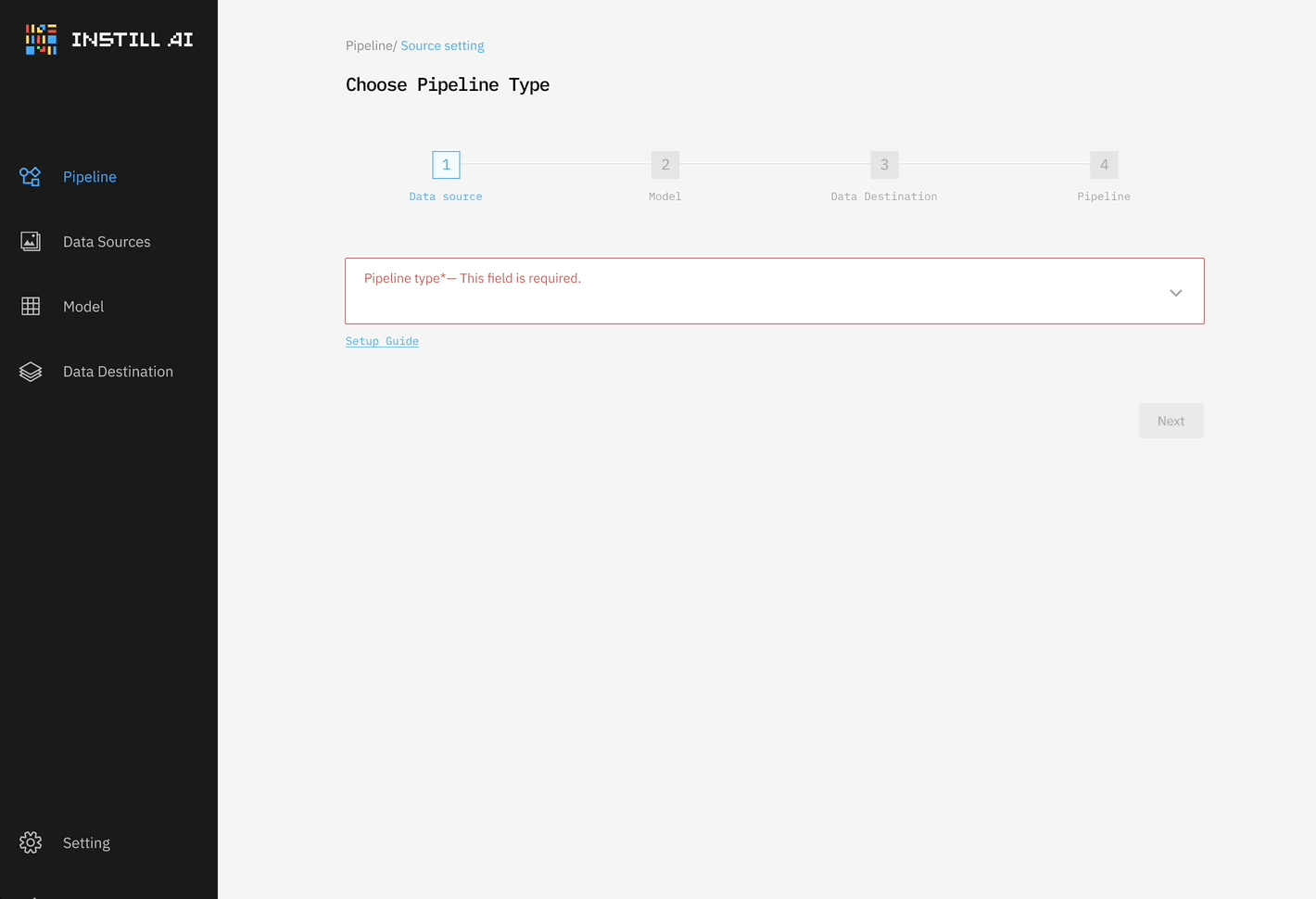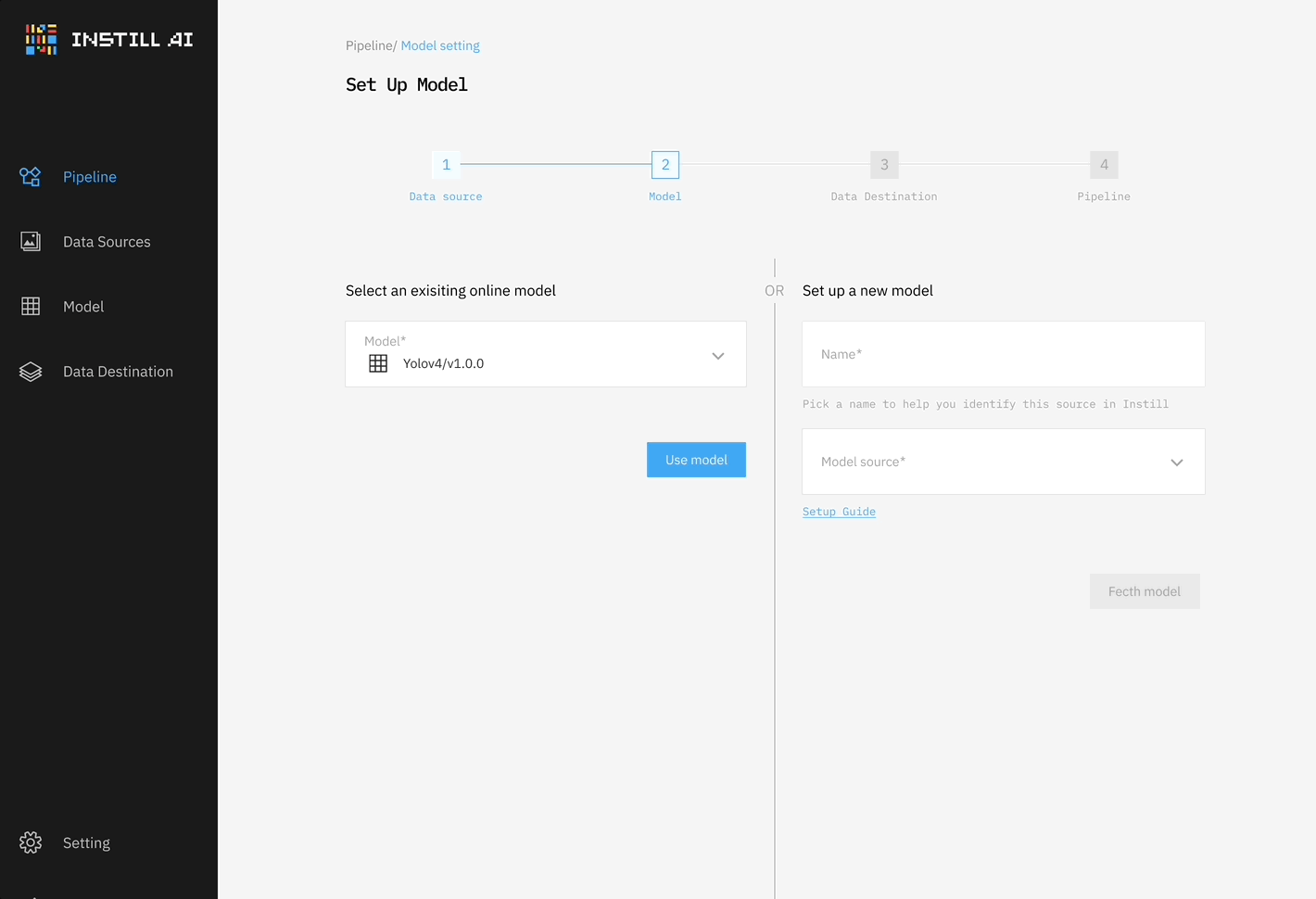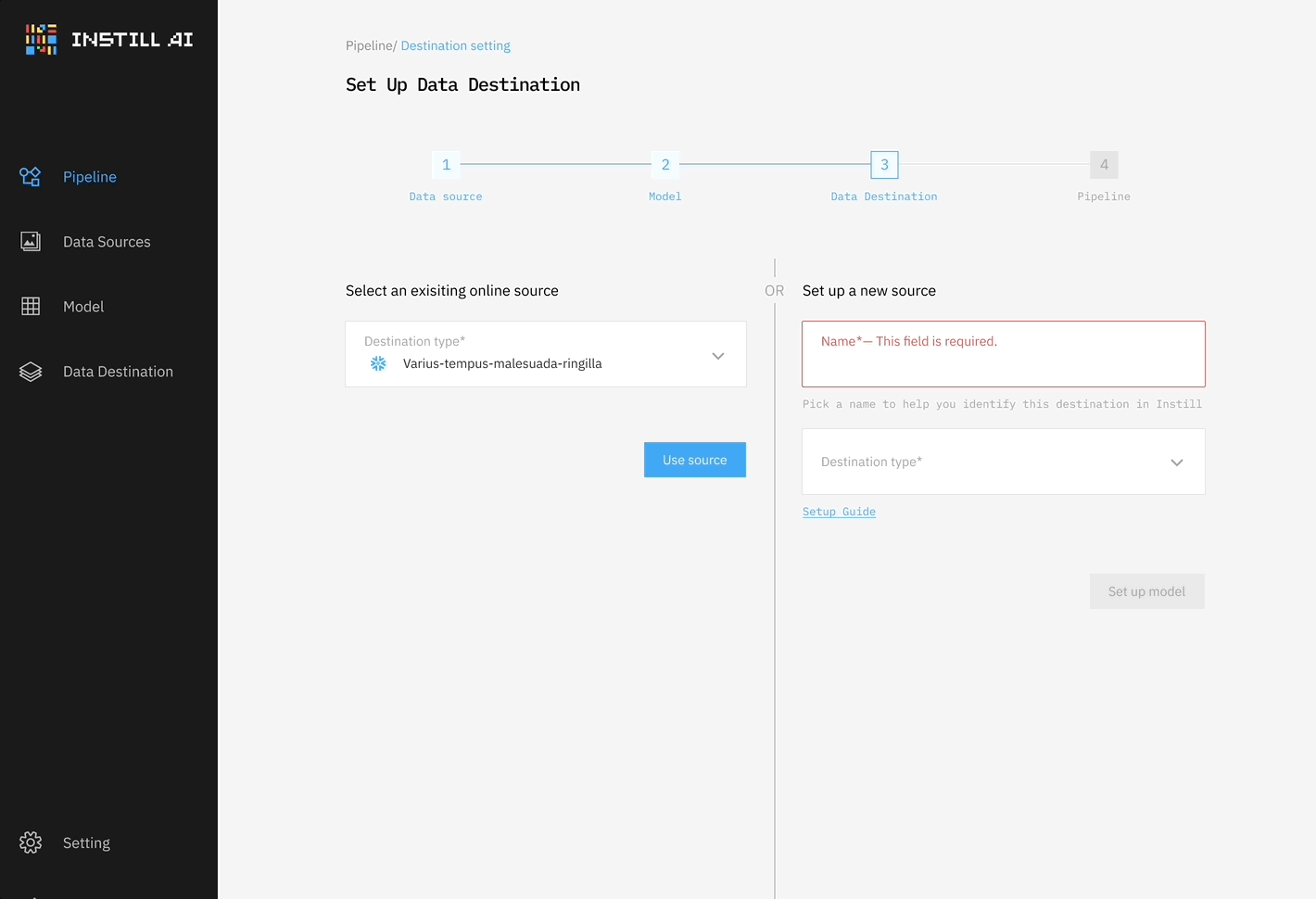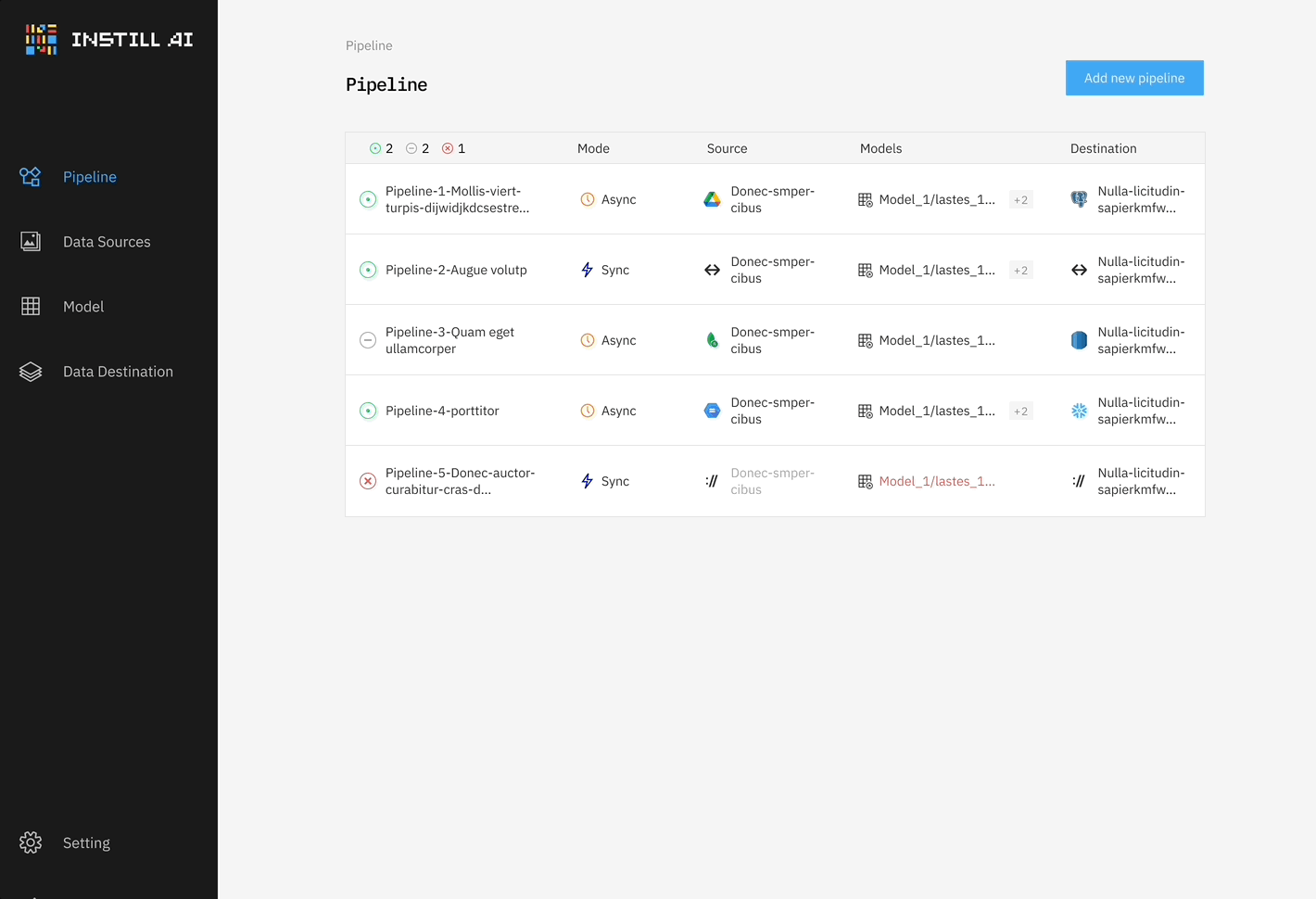
然而,我們很快意識到這種方法的局限性,它過於僵化,並且只解決了部分問題。非結構化資料 ETL 與傳統資料 ETL 有根本上很大的不同,傳統資料 ETL 主要是通過操作資料庫結構反覆地轉換結構化資料。相比之下,非結構化資料 ETL 需要不同的 DL 模型來完成不同的轉換任務,並且通常需要一併處理多模態資料。
例如,一個高精度的 PDF 文檔分析器可能需要 PDF 解析器、VLM 或 OCR 模型來同時將圖表內容轉化為 Markdown 格式,然後使用 LLM 甚至擴散模型來生成最終的商業報告。
許多供應商提供一步式非結構化資料 ETL,如 Unstructured.io、Reducto、Google Cloud Document AI、Amazon Textract(用於 PDF 解析),Kling AI 和 Pika(用於影片生成),以及 ElevenLabs 和 HeyGen(用於語音生成)。無論它們是否提供第三方整合的 API,這些解決方案都可以看作是一種對某種特定應用進行一步式非結構化資料 ETL 處理。
我們認為非結構化資料 ETL 應該要更加靈活且多功能,並要能將不同類型的資料和模態納入迭代處理中(見圖 2)。畢竟,資料 ETL 的本質(也被稱為資料清洗),就是要不斷提煉資料,直到其價值被完全萃取出來。


無程式碼管道構建器(2023年)
有了 MVP 的開發經驗後,我們將重點轉向處理資料的多功能性,於是我們開發了一款非結構化資料 ETL 管道工具,讓其具有標準化接口以連接所有的第三方整合元件。也就是在此階段,我們的開源項目 Instill Core 問世。
Instill Core 採取了 Unix 哲學 - “Do one thing and do it well.” 它是基於雲原生、API 優先(RESTful + gRPC)、高度模塊化的設計。後端核心使用 Go 實現,並提供 Python 和 TypeScript SDK。選擇這樣的技術棧是為了模塊化、可擴展性和可擴展性,同時也優先考慮了性能和安全性。
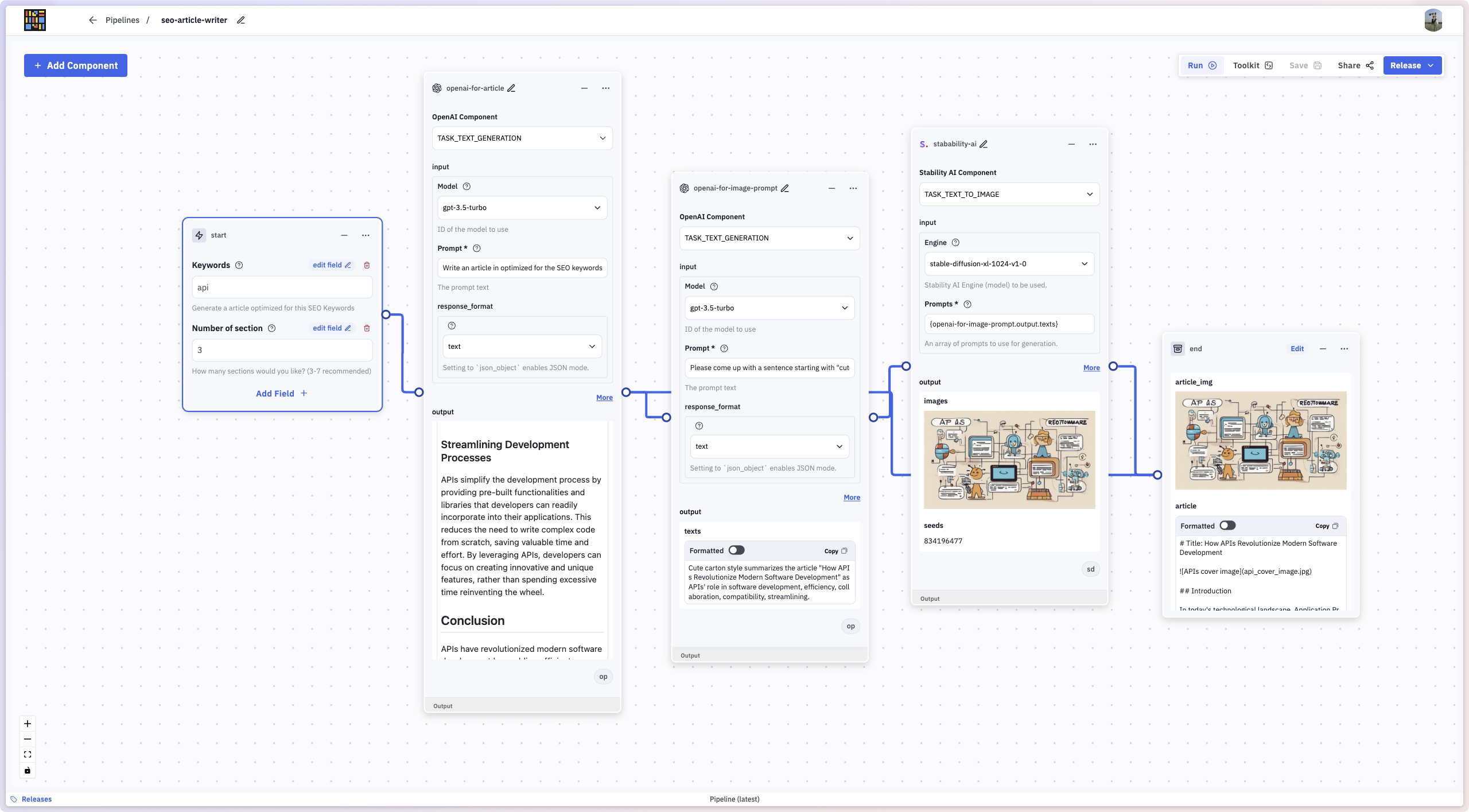
除了核心功能外,我們還構建了許多與 AI 和資料供應商的整合元件,使 Instill Core 內的非結構化資料能夠無縫進行重構和組合(見圖 3)。Instill Core 主要由三個模塊組成:
- Pipeline,用於非結構化資料 ETL。
- Model,用於託管 DL 模型。
- Artifact,用於有狀態服務資料存儲(例如,blob 存儲,向量資料庫)。
此時,Instill Core 提供了一個拖放式的無程式碼管道構建器,專為AI構建者量身定制(見圖 4)。
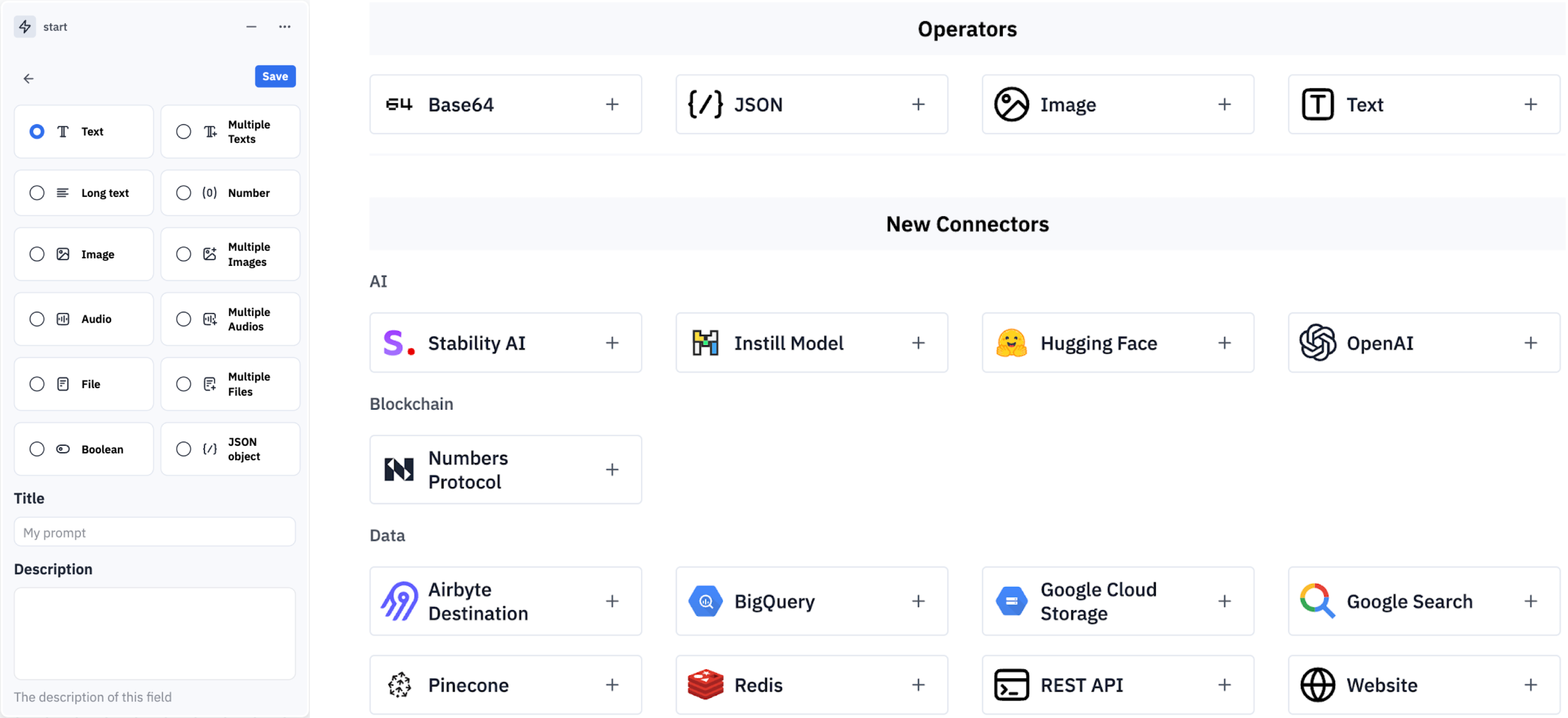
然而,在後 ChatGPT 時代(2023 年之後),數百家新創公司湧現,提供類似的無程式碼 UI/UX 解決方案用於生成式 AI,其中包括 Flowise、Langflow、Stack AI、VectorShift、Dify 等。甚至連傳統的資料 ETL 工具如 Airflow、n8n、Zapier、Make 等,也陸陸續續加入了 LLM 整合功能。
然而,儘管這些工具(包括當時的 Instill Core)展示了其多功能性,我們卻開始質疑這種設計的可用性和可維護性。因為,隨著 ETL 管道變得越來越複雜,通過無程式碼的界面去管理這些管道,其實並不會比較輕鬆。
試想,如果沒有人會想要管理維護一坨亂七八糟的程式碼庫,那怎麼又會有人會想要管理一坨錯綜複雜、千絲萬縷的資料管線呢?
再者,儘管無程式碼 UI/UX 能夠使不懂技術的用戶也能夠構建和運行資料管道,但我們的目標受眾其實是開發者,一群懂技術、會寫程式的人。作為開發者,我們知道一定有更好的方法。
低程式碼管道配方(2024年)
宣告式管理(Declarative Management)為這樣的問題,提供了一個很好的解決方案。在進行了數千次拖放操作和無盡的滑鼠點擊構建管道後,我們決定是時候繼續前進,開始思考如何使用 YAML 配方來構建和維護管道。
會有這樣的想法,主要是受到我個人在管理 Kubernetes 時的經驗啟發。使用 Kubernetes 集群總是令我感到安全且管理容易,因為 YAML 檔案可以版本控制並且具有高可讀性。透過 Terraform 等工具,我們還可以進一步實踐基礎設施即程式碼(Infrastructure as Code,IaC),將整個基礎設施轉化為程式碼庫。
那麼,管道即程式碼(Pipeline as Code,PaC)有可能嗎?當然可以!這個概念其實類似於 Airflow、Prefect 和 Dagster 中基於 Python 的領域特定語言(Domain-Specific Language,DSL),只是我們更喜歡用 YAML 作為 DSL。
一些開發者可能會不喜歡基於 YAML 的程式管理實作,認為檔案內容的冗長性會使開發者失去大局觀。我們確實也有同樣的疑慮,於是我們選擇了一條魚與熊掌都能兼得的方案,將 YAML 管道配方編輯器和管道預覽畫布並排放在一起不就好了!這就是目前版本的 Instill Core 的設計方式,並且我們還有一長串 UI/UX 改進計劃,持續不斷地優化產品體驗是我們公司的核心文化。
今天,你可以使用 Instill Core 來構建聊天機器人、植物表型分析器、複雜 PDF 解析器、網站爬蟲,甚至為 AI 代理人工具構建進階 RAG 系統。等等。。。AI 代理人?這又是我在什麼賣弄學問的話術?其實不然,在 Instill AI,我們將所有 AI 的軟體程式和任務都視為非結構化資料 ETL 管道。影片 1 和影片 2 展示了一些 AI 代理人工具的實際例子。
使用 YAML 配方構建管道確實非常棒,我們喜歡這個方案,我們的早期用戶也喜歡這種方式。但對於作為一個軟體產品開發愛好者,並具有高標準的我們,我們知道,一定有更好的方法!
對話式的 Instill AI(2025年)
現在就是未來,未來就是現在。
參考 GitHub Copilot、Cursor 和 Windsurf 為 AI 使用者直接生成程式碼,而 Bolt.new 和 Replit 甚至更進一步使他們能夠打造全棧軟體。同樣地,Instill Core 中的資料管道 YAML 配方現在也應該可以由 AI 生成。這標誌著資料 ETL 工具的新篇章,並為非技術 AI 使用者打開了一道可以更完整榨取資料價值的大門。
基於這波勢頭,我們目前全面轉向開發一個基於對話式的多代理人框架 Instill AI(是的,這就是產品名稱),旨在幫助知識工作者從所有類型的資料中提取價值並自動化重複任務。Instill AI 是 100% 基於 Instill Core 所打造,利用非結構化資料 ETL 管道作為其代理人的工具。即使我們 Instill AI 仍然專注於非結構化資料價值開發,但它現在將通過基於對話式的使用者介面,自動化使這些功能,讓所有的 AI 使用者都能使用。
與一般常見,基於 GPT 客製化的 AI 產品相比,Instill AI 將在以下方面賦能知識工作者:
- 探索:獲得相關知識的 360º 視角。
- 挖掘:深入研究特定主題。
- 分析:檢查資料點彼此之間的關係、差異,並從多個資料點中提取洞見。
- 非結構化資料 ETL:處理和提取大量非結構化資料(包括文檔、網站、圖片、影片和聲音)中的有價值見解。
- 忠實性:獲得您可以信任的高保真答案。
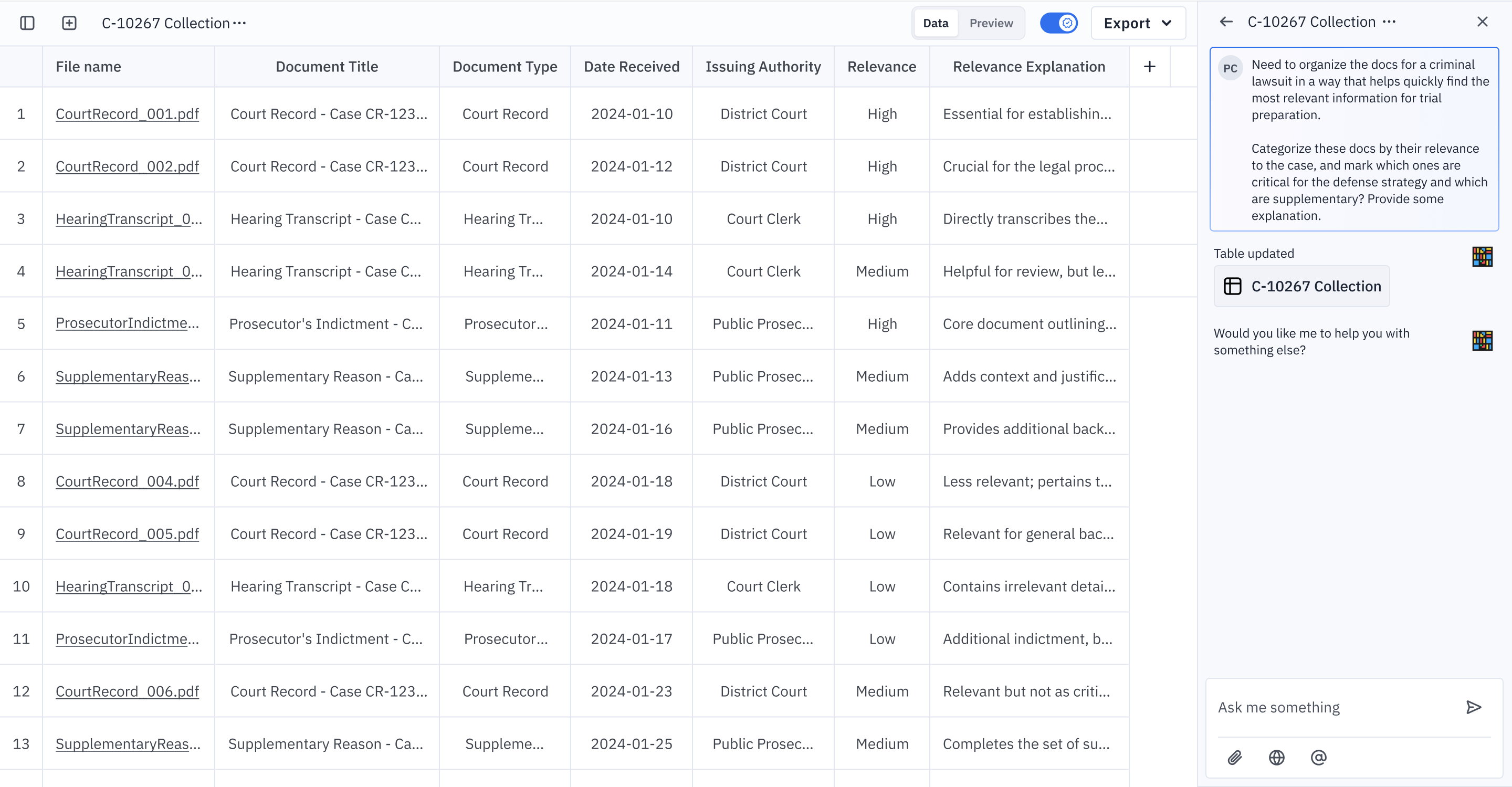
您也可以將 Instill AI 視為一個 AI 代理人,它可以清理、處理和組織資料,使您能夠高效地簡化和優化知識工作流程(見圖 5)。
Instill AI 於今年 3 月封測發布後,我們會馬上終止 Instill Cloud,也就是 Instill Core 的全託管雲服務。如果您希望成為 Instill AI 的早期用戶,同時繼續通過後端控制台使用 Instill Core 的核心功能,請馬上註冊 Instill AI 等候名單,並跟我們分享您的非結構化資料 ETL 管道使用案例,我們將會根據情況與您聯繫並授予訪問權限。
展望未來
本文是我三年來打造 AI 產品旅程的反思,以及我們目前所處的位置。我理解每個人對軟體工具和 AI 產品應如何發展有不同的看法。話雖如此,反正我現在堅信基於對話式的 UI/UX 會是每個人利用 AI 最直接的方式。然而,AI 的應用其實不必侷限於聊天、搜尋、程式碼補全或內容生成,而資料 ETL 也不必只依賴拖放式無程式碼 (no-code) 介面或冗長的 DSL 低程式碼(low-code),這些技術其實可以共同發展演化,成就更先進的軟體資料系統。
作為一家小而美的新創公司,我們最大的優勢就是速度。但無論我們速度能有多快,如果方向是錯的,那我們將不會取得任何進展。我們本來可以追求僅針對 AI 建構者的無程式碼管道構建器,或是低程式碼管道配方這樣的產品,來進行市場佈局,但我們選擇不這樣做,相反的,我們重押了生成式 AI 的發展潛力與多功能性,平行同步與之一起演化我們的產品。這不僅僅是因為作為新創公司,輕巧的我們可以這麼做,也是因為我們清楚地知道我們想做什麼、該做什麼、能做什麼,以及市場真正的需求是什麼,我們完全有機會可以服務更廣大的 AI 使用者群。
這是一堂得來不易的產品旅程,我們一路走來,從為了 AI 建構者所打造的無程式碼到低程式碼解決方案,到現在將重點轉向為所有 AI 使用者提供基於對話式的 AI 代理人,希望讀者您能在這篇文章中找到一些有用的經驗借鏡。我一直有個想像,一種能夠理解任何物理信號,並且有智慧地回應任何人類語言指令的電腦系統。如今這個願景比以往任何時候都更接近現實,我很慶幸能夠活在這一千載難逢機會的當下。
詞彙表
生成式 AI
- 生成式 AI 包括大型語言模型(LLMs)、視覺語言模型(VLMs)、大型多模態模型(LMMs)、大型推理模型(LRMs)和擴散模型,能夠執行文字生成、程式碼完成、圖片到文字、圖片到圖片、文字到語音(TTS)、語音到文字(STT)等任務。
- 大型語言模型(LLMs),如 GPT-4o,經過大量文字資料集的訓練,能夠生成類似人類的文字。
- 視覺語言模型(VLMs),如 OpenAI-o1、OpenAI-o3-mini 和 LLaVA-CoT,經過文字和圖片資料集的訓練,能夠生成類似人類的文字和圖片。
- 大型多模態模型(LMMs),整合了多種資料類型,如文字、圖片、影片和聲音,以增強跨模態的理解和生成。
- 大型推理模型(LRMs),專注於高級推理能力,旨在提高問題解決和決策過程,如 OpenAI-o1、OpenAI-o3-mini 和 DeepSeek-R1。
- 擴散模型(Diffusion Models),如 DALL-E 和 Stable Diffusion,通過逐步細化隨機噪聲以匹配給定的文字提示來生成圖片。
傳統資料 ETL vs. 非結構化資料 ETL
- 資料 ETL(Extract, Transform, Load,提取、轉換、加載)是一種資料整合過程,從各種來源提取資料,將其轉換以適應操作需求,並加載到目標系統(如資料倉庫)中。它也被稱為資料清洗或資料整理。
- 非結構化資料 ETL 涉及從各種非結構化來源(如文檔、圖片或影片)提取資料,將其轉換為適合分析的結構化格式,並加載到資料倉庫或資料庫等目標系統中。
| 傳統資料 ETL | 非結構化資料 ETL | |
|---|---|---|
| 資料類型 | 結構化資料(例如,表格、關係資料庫)。 | 非結構化資料(例如,文字、圖片、影片、PDF、日誌)。 |
| 提取來源 | SQL 資料庫、CSV 文件、電子表格。 | 文檔、電子郵件、社交媒體、多媒體、日誌。 |
| 轉換過程 | 模式映射、聚合、資料清理、索引。 | LLM、Embedding、OCR。 |
| 常用工具 | Apache Spark、Informatica、Airflow 等。 | Instill Core、LangChain、Hugging Face、Unstructured.io 等。 |
| 加載目的地 | 資料倉庫(Snowflake、BigQuery、Redshift)。 | 向量資料庫(Pinecone、ChromaDB)、文檔存儲(Elasticsearch、MongoDB)、blob存儲(GCS、S3、MinIO) |
| 最終用例 | BI 儀表板、財務報告、分析。 | AI 驅動的搜索、RAG(檢索增強生成)、聊天機器人、內容分析。 |
AI 建構者 vs. AI 使用者
- AI 建構者是設計、開發和優化 AI 產品的開發者,利用機器學習、軟體開發和資料科學的技能來打造 AI 驅動的技術。相比之下,AI 使用者是利用這些 AI 產品來提高生產力的專業人士,將 AI 應用於自動化、內容打造、資料分析和決策等領域。建構者使用 PyTorch、TensorFlow 和 Hugging Face 等工具來構建 AI 解決方案,使用者則與 ChatGPT、GitHub Copilot 和 AI 驅動的分析工具等 AI 應用程序交互,以簡化他們的工作流程。請參閱下表。
| AI 建構者 👩🔧👨🏻🔧 | AI 使用者 👩💼👨🏻💼 | |
|---|---|---|
| 定義 | 設計、開發和構建 AI 產品的人。 | 使用 AI 產品來提高生產力的人。 |
| 主要目標 | 打造和優化 AI 驅動的技術。 | 利用 AI 提高效率和決策能力。 |
| 關鍵活動 | 開發機器學習模型、微調 LLMs、整合 AI API、構建 AI 驅動的應用程序。 | 使用 AI 進行自動化、內容生成、資料分析、研究和溝通。 |
| 所需技能 | AI/ML 工程、軟體開發、資料科學、產品管理。 | 各自領域的專業知識、有效與 AI 工具交互的能力。 |
| 示例 | OpenAI、Hugging Face、Google 或打造 AI 驅動應用程序的新創公司的工程師。 | 使用 ChatGPT 的作家,利用 AI 分析的營銷人員,使用 AI 輔助編程工具的編碼員。 |
| 使用工具 | Instill Core、PyTorch、TensorFlow、Hugging Face、LangChain、OpenAI API。 | Instill AI、ChatGPT、Midjourney、GitHub Copilot、AI 驅動的自動化工具。 |