Reimagine Unstructured Data ETL
February 14, 2025
Generative AI is revolutionizing software—how does it transform the way we utilize unstructured data like text, images, and videos?
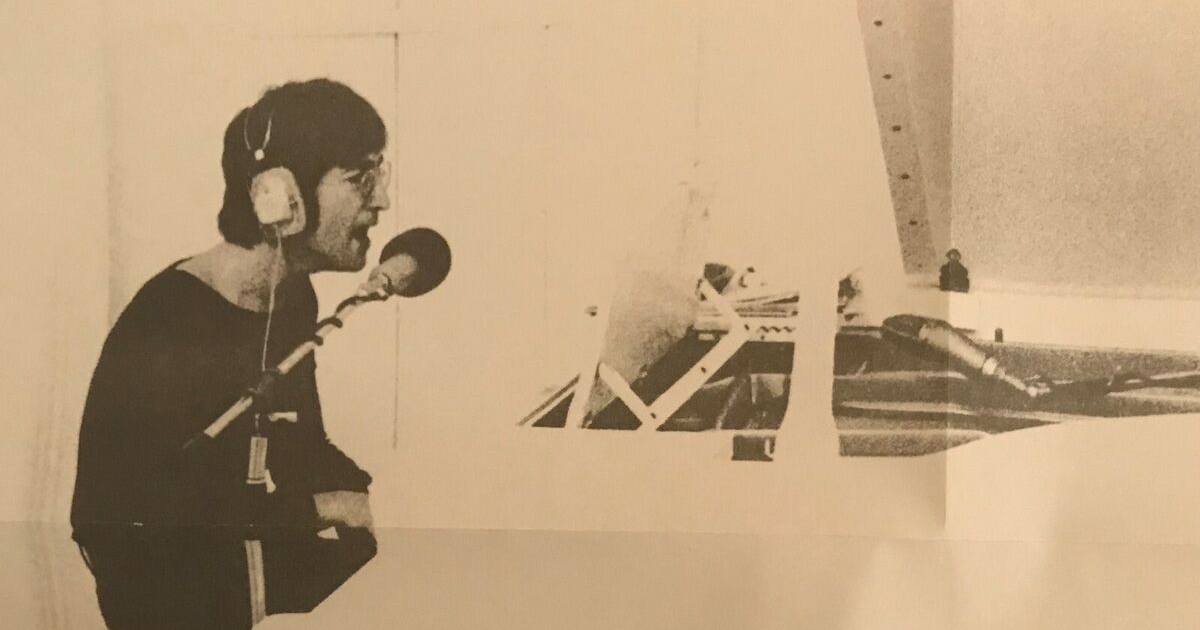
Imagine a computer system that interprets any physical signal and intelligently responds to any language instruction.
This article shares insights from my experience in the rapidly evolving AI and data industry over the past three years, detailing our journey at Instill AI in building an unstructured data ETL platform and AI-first product. We explore the multiple iterations we’ve made—shifting from a no-code to a low-code data pipeline tool for AI Builders, and now evolving into a chat-based UI/UX for all AI Users.
As foundation models continue to advance, they have transformed software development practices—from traditional imperative programming to prompt engineering, and from frameworks like Chain-of-Thought (CoT) and ReAct to agentic workflows, enabling more autonomous, self-contained systems. But will this trend continue reshaping software engineering best practices? By the end of this article, you may find yourself arriving at the same conclusion as I did.
Note: Before we dive deeper, you might familiarize yourself with the terms used throughout the article in the Glossary.
Generative AI = A new software enabler
I come from a Computer Vision (CV) and Machine Learning (ML) background, having witnessed the evolution of these fields from traditional CV algorithms—such as Histogram of Oriented Gradients (HoG) and Scale-Invariant Feature Transform (SIFT)—and classical ML methods like Support Vector Machines (SVM), Random Forest (RF), and AdaBoost, to today’s end-to-end Deep Learning (DL)-based foundation models that are solving (nearly) all ill-posed problems.
What impresses me the most is not just how powerful these foundation models have become, but also how disruptive they have been in software tooling. We’ve seen OpenAI Research integrating external web search into agentic workflows to conduct an in-depth research for a certain topic, OpenAI-o1 and DeepSeek-R1 performing self-reflection during inference to improve reasoning and answer accuracy, and OpenAI Operator and Anthropic Computer Use executing Robotic Process Automation (RPA) tasks by controlling a user’s keyboard and mouse.
Since 2012, the first DL hype centered around Convolutional Neural Networks (ConvNets) and their ImageNet breakthrough in CV. (At that time, this was already the third AI hype cycle, following the Symbolic AI era.) However, ConvNets never fully surpassed expectations because they relied primarily on supervised learning, which requires massive amounts of labeled data. Furthermore, pre-trained models failed to generalize well due to the highly dynamic and unpredictable nature of image and video content.
Then, in 2017, Transformers arrived and completely changed the game. Emerging from Natural Language Processing (NLP), they eliminated the need for labeled data, thanks to autoregressive self-supervised learning. Since human languages naturally generalize well, Transformer-based models proved highly effective not only in text tasks but also across different modalities—such as text-to-image and image-to-text. Today, we refer to this entire landscape as Generative AI, covering all AI-powered content generation for various tasks.
By November 2022, following the success of GPT-2 (a 1.5B parameter model in 2019) and GPT-3 (a massive 175B parameter model in 2020), GPT-3.5, optimized for chat-based interactions, marked the birth of ChatGPT. The success of the GPT family can largely be attributed to Scaling Laws, rather than any mysterious “secret sauce.” Based on this principle, any organization with sufficient GPU compute power can theoretically reproduce similar results—though not necessarily easily, but pragmatically.
Since then, we have witnessed a global battle in foundation models. Initially, the competition was centered in the U.S. and EU, with Anthropic, Cohere, Mistral, and Google as the key players. Now, Chinese AI firms such as DeepSeek and MiniMax have joined the race, offering models with API prices up to 30× cheaper. The trend is clear: Foundation models are rapidly becoming commoditized, transitioning into common infrastructure that software platforms and applications can heavily benefit from.
The evolving Modern Data Stack (MDS)
From 2010 to early 2024, MDS barely evolved, while AI advancements skyrocketed. Now, the impact of AI on the data industry is getting inevitable and disruptive. The signs are already here:
- Databricks’ Series J founding round, raising $10 billion and valuing the company at $62 billion, investing in new AI products.
- Snowflake acquired DataVolo for its unstructured data streaming capabilities.
- DataStax acquired Langflow for its no-code AI workflow builder.
And this is just the beginning. The AI revolution is not only transforming software development—it’s redefining the entire data ecosystem. The most exciting part? We have the opportunity to shape it!
An iterative journey
How has Instill AI been adapting and evolving within the broader landscape? We’ve been deeply reflecting on the most efficient and effective way to achieve our ultimate goal—making AI accessible to everyone. Our mission is to empower people to automate daily tasks, enhance personal productivity, and free up time from tedious, repetitive chores.
As an early-stage startup, our biggest challenge is achieving product-market fit (PMF)—a continuous, iterative process rather than a one-time milestone. To sustain our financial runway, we must carefully balance innovation with long-term viability. While Artificial General Intelligence (AGI) might seem like the ultimate solution, we believe it alone won’t achieve our goal. Moreover, although we have the technical expertise, we lack the funding to research and train foundation models. Instead, we take a pragmatic approach, recognizing that software tooling must evolve alongside AI. Rather than focusing solely on AI models, we prioritize data tooling, understanding that a model alone cannot unlock the full AI value chain.
One-step Unstructured Data ETL (2022)
Based on our thesis, we originally identified our target audience as Data Engineers, Data Scientists, AI Engineers, and AI Researchers—the AI Builders who need to construct unstructured data ETL pipelines.
Drawing inspiration from dbt (which handles the “T” in ETL for data transformation) and Airbyte (which facilitates the “EL” in ELT for data movement), we initially built a system that connected data sources and destinations with a single DL model—whether an LLM, STT/TTS model, or object detection model—as shown in Figure 1. This was our very first MVP, developed before our seed funding round, to showcase how unstructured data could be processed in an ETL framework.
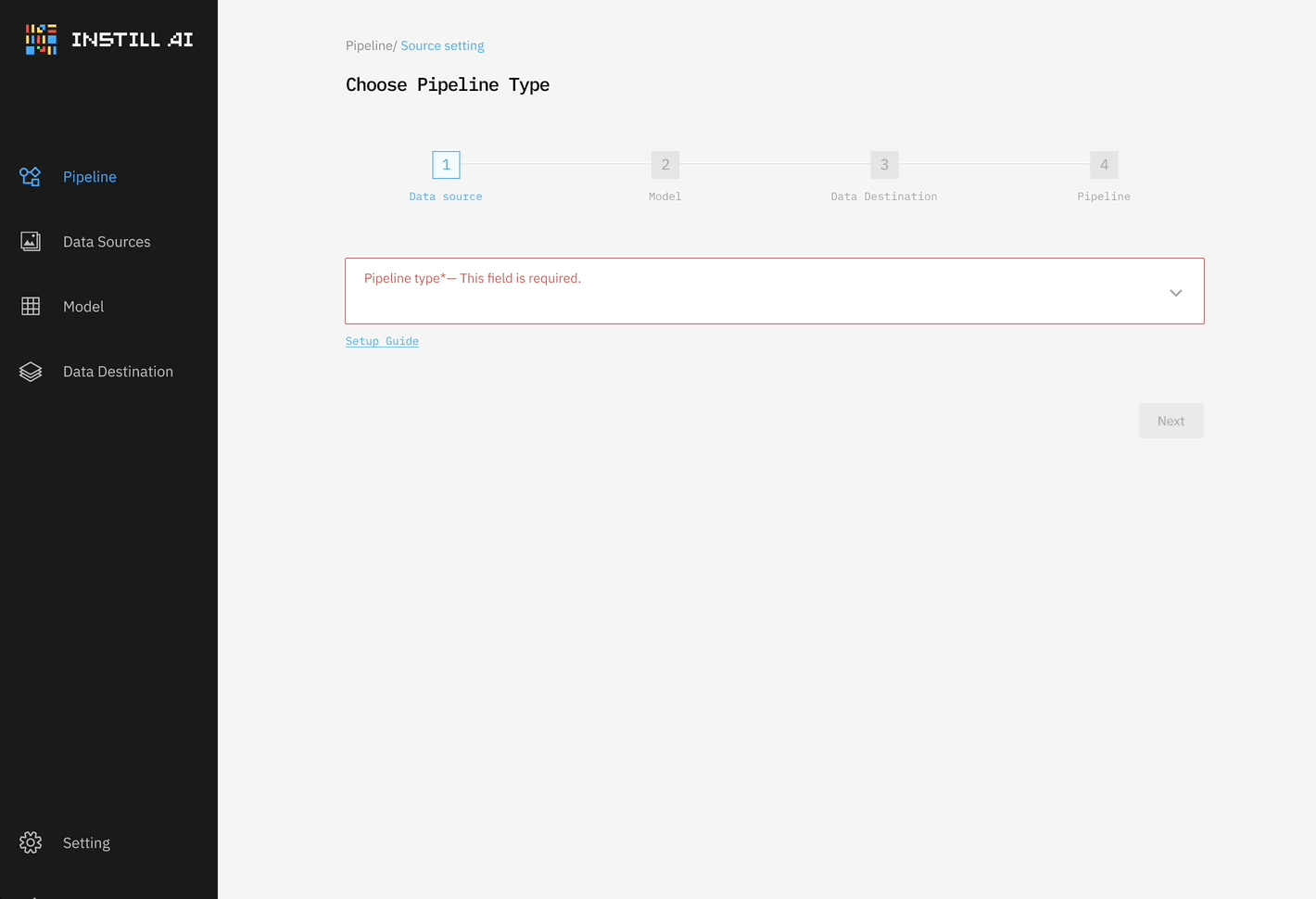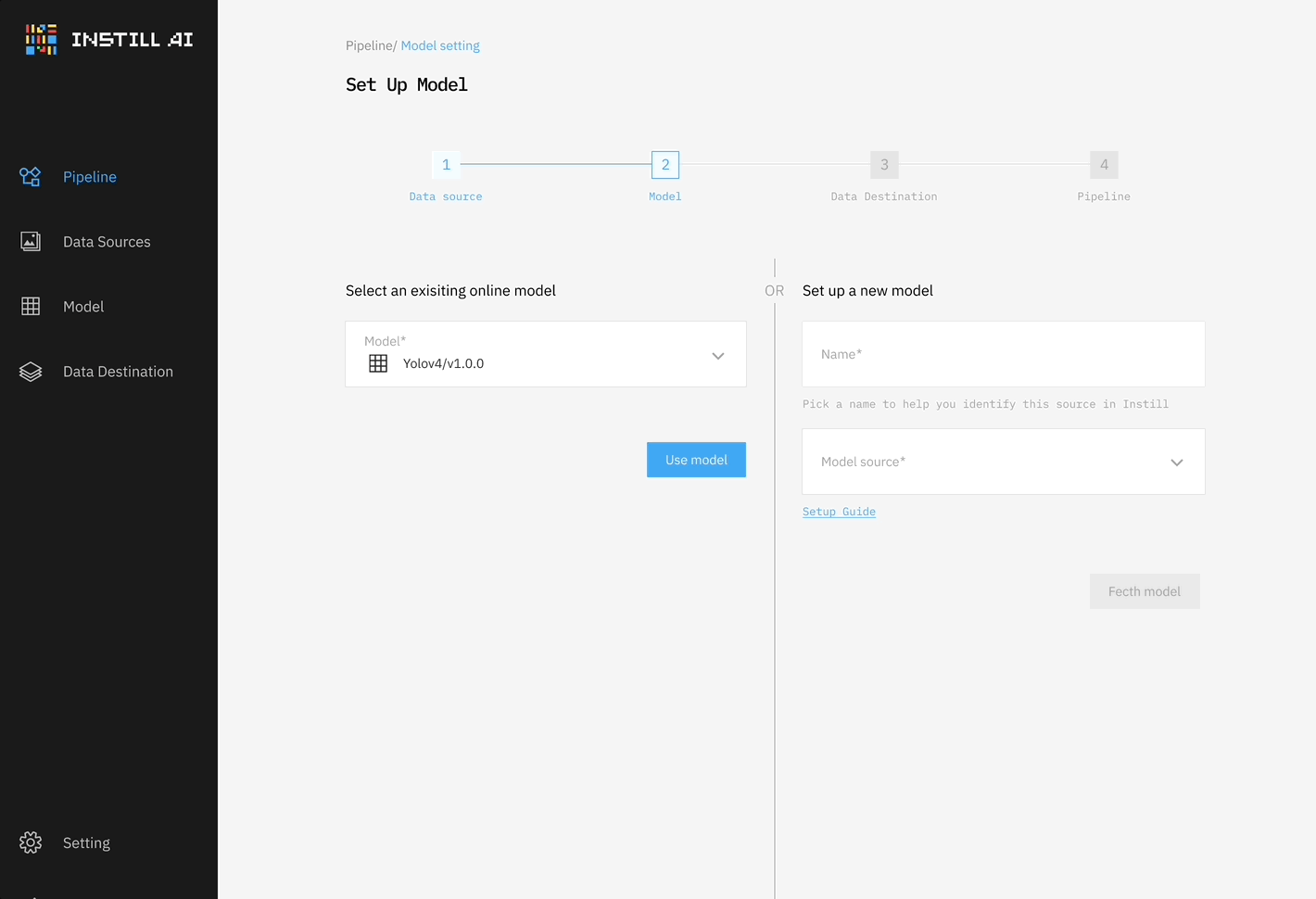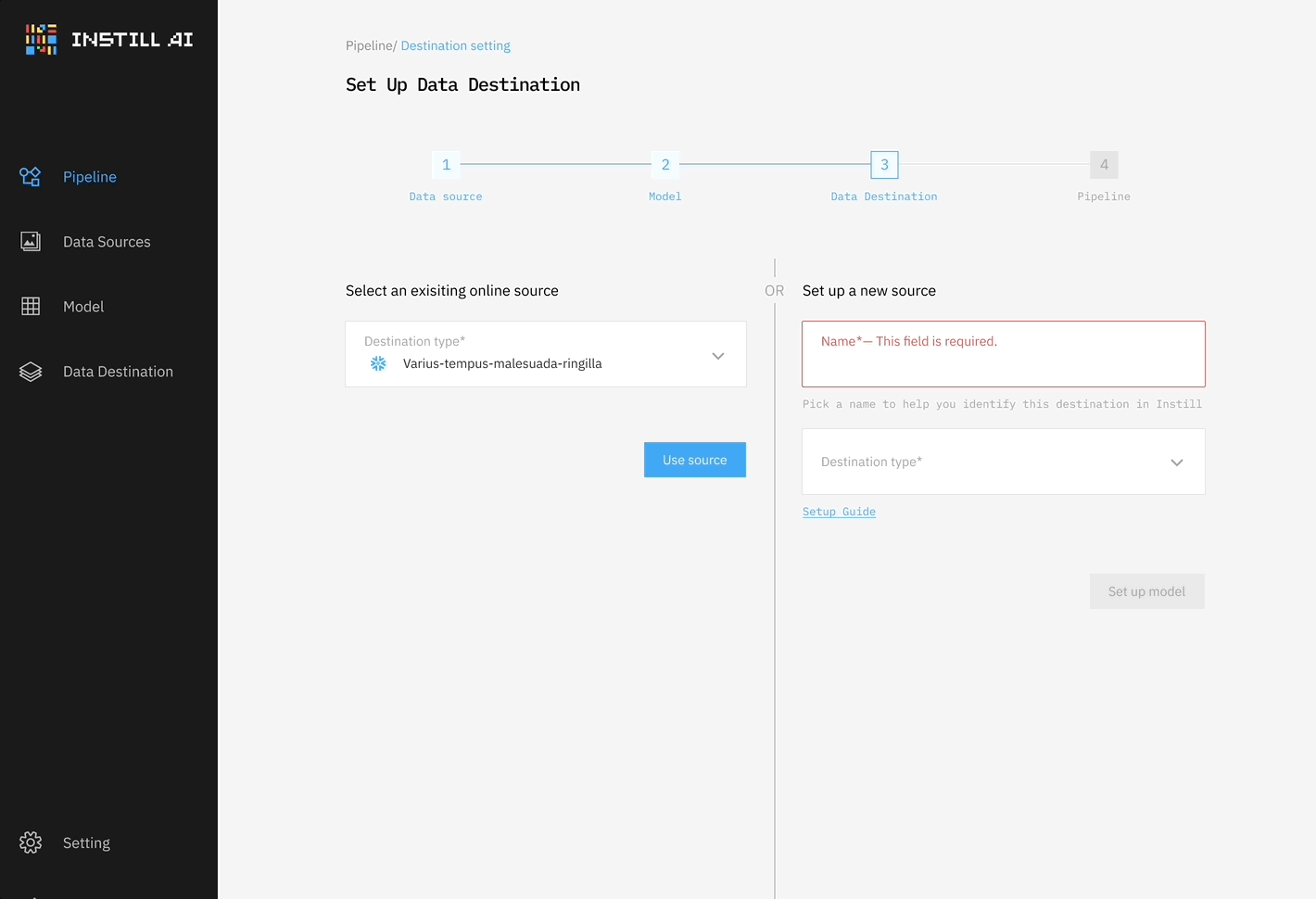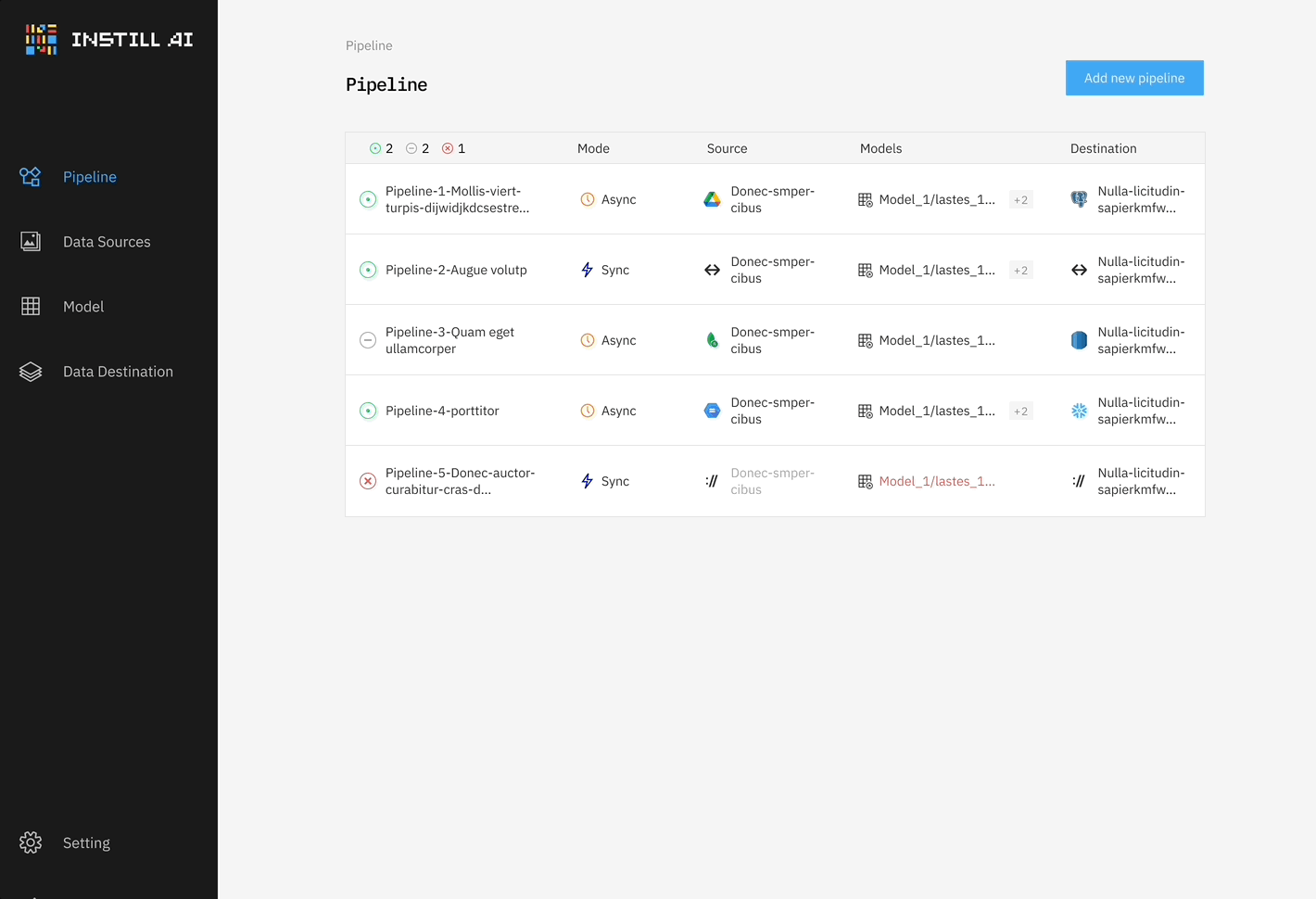
However, we quickly realized the limitations of this approach—it was too rigid and solved only part of the problem. Unstructured data ETL is fundamentally different from traditional data ETL where structured data can be transformed repeatedly by operating on table schemas. In contrast, unstructured data ETL requires different DL models for different transformation tasks, often processing data in multiple modalities.
For example, a high-accuracy PDF document analyzer might require a PDF parser, a VLM, or an OCR model to extract graph content into Markdown format, followed by an LLM or even a diffusion model to generate a business intelligence (BI) report.
Many vendors offer one-step unstructured data transformations, such as Unstructured.io, Reducto, Google Cloud Document AI, and Amazon Textract (for PDF parsing), Kling AI and Pika (for video generation), and ElevenLabs and HeyGen (for voice generation). Whether or not they provide APIs for third-party integration, these solutions can be seen as applications performing specific transformations on specific types of unstructured data.
We believed that unstructured data ETL needed to be more versatile, incorporating different data types and modalities in iterative processing (see Figure 2). After all, the essence of data ETL—also known as “data washing”—is to refine data continuously until its value is fully extracted.


No-code pipeline builder (2023)
Learning from this, we shifted our focus toward data versatility, developing a unified unstructured data ETL pipeline tool with a standardized interface to connect all components. At this stage, the open-source project Instill Core was first consolidated.
Instill Core was built on the Unix philosophy—“Do one thing and do it well.” It is cloud-native, API-first (RESTful + gRPC), and highly modular. The backend core is implemented in Go, with Python and TypeScript SDKs available. This tech stack was chosen for modularity, extensibility, and scalability, while also prioritizing performance and security.
Beyond core functionality, we built integrations with AI and data vendors, enabling seamless composition and assembly of unstructured data within Instill Core (see Figure 3). Instill Core consists of three main modules:
- Pipeline – For unstructured data ETL.
- Model – For hosting DL models.
- Artifact – For stateful data storage (e.g., blob storage, vector databases).
At this point, Instill Core provided a drag-and-drop no-code pipeline builder tailored for AI Builders (see Figure 4).
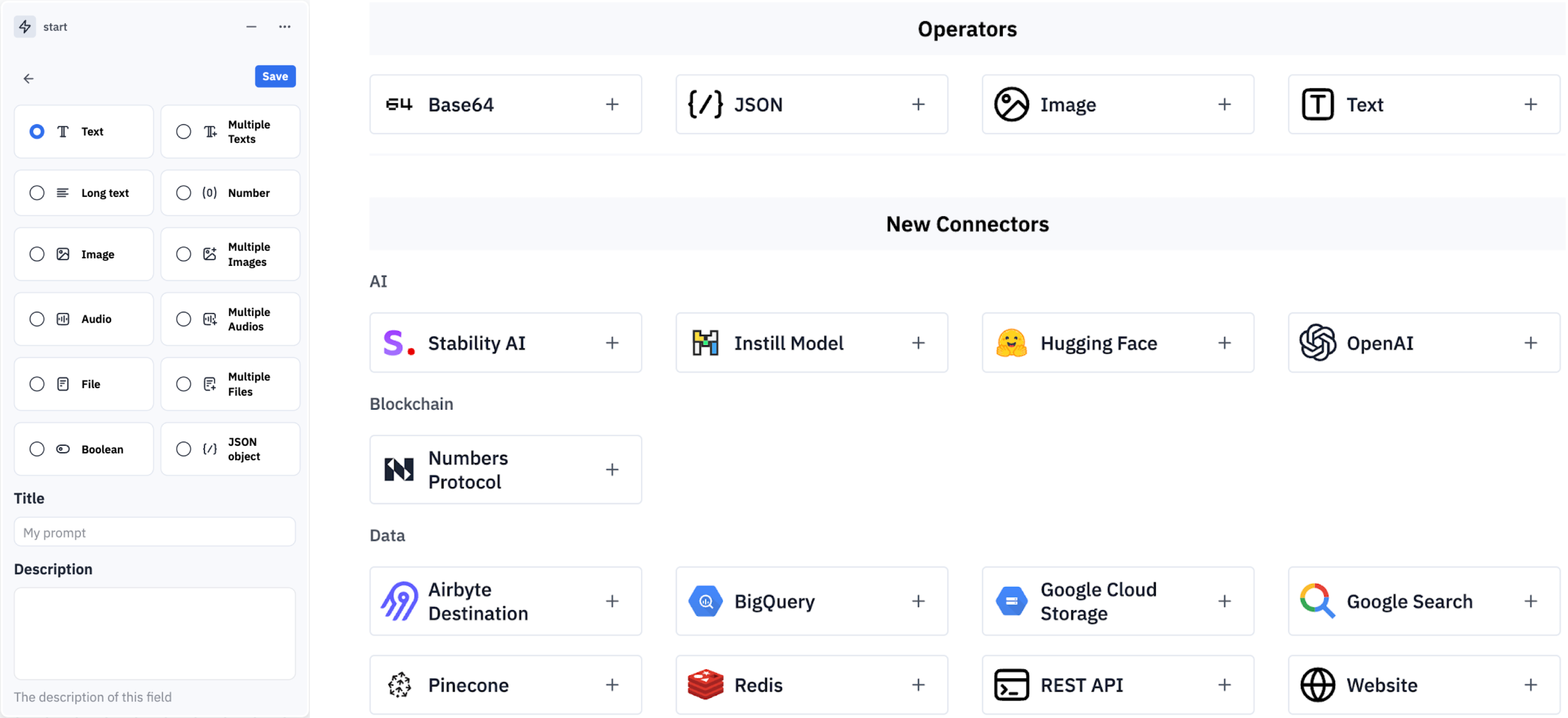
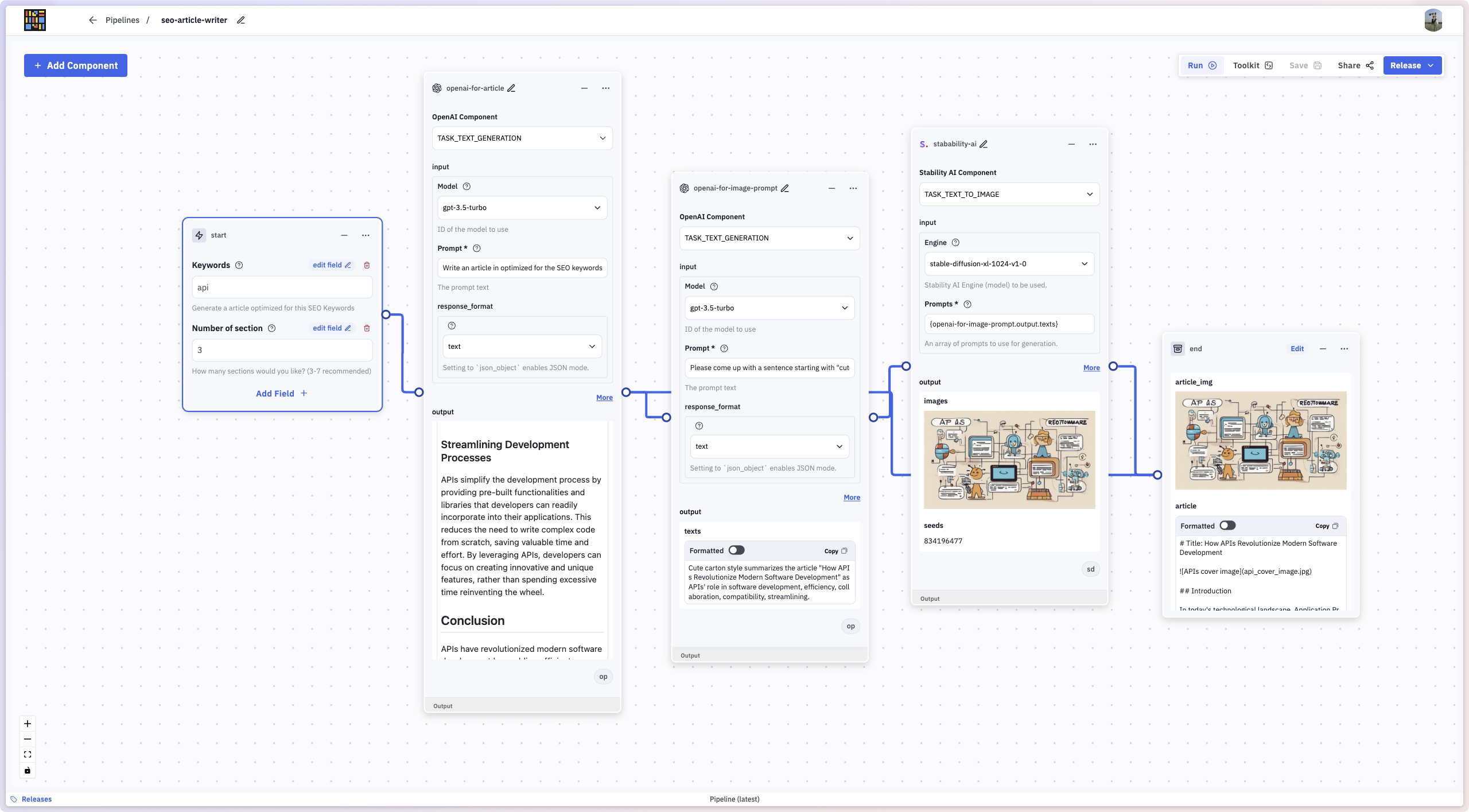
However, in the post-ChatGPT era (after 2023), hundreds of startups emerged, offering similar no-code UI/UX solutions for Generative AI, including Flowise, Langflow, Stack AI, VectorShift, and Dify. Even traditional data ETL tools like Airflow, n8n, Zapier, and Make have since introduced LLM integrations.
While these tools (including Instill Core at the time) showcased versatility, we began to question their usability and maintainability. As ETL pipelines grew more complex, managing them through no-code interfaces became increasingly overwhelming.
Think of it this way—nobody wants to maintain spaghetti code, so why would anyone want to manage a spaghetti canvas? The design inevitably leads to a “death by a thousand clicks” scenario sooner rather than later.
Moreover, although no-code UI/UX enables non-technical users to build and run pipelines, our target audience (TA) is actually developers—people who can code. As developers, we knew there had to be a better way.
Low-code pipeline recipe (2024)
Declarative management offers a powerful solution to this problem. After thousands of drag-and-drop actions and endless mouse-clicking to build pipelines ourselves, we decided it was time to move on—to build and maintain pipelines using YAML recipes.
This idea was inspired by my personal experience managing Kubernetes. Working with Kubernetes clusters has always felt secure and manageable because YAML resources are versionable and human-readable. With tools like Terraform, we can take this further by practicing Infrastructure-as-Code (IaC)—treating infrastructure like a codebase.
So, what about Pipeline-as-Code (PaC)? Absolutely yes! The concept is similar to Python-based Domain-Specific Languages (DSLs) found in Airflow, Prefect, and Dagster, but we prefer YAML as the DSL.
Some developers might criticize YAML-based programming, arguing that its verbosity makes it difficult to grasp the big picture. We shared that concern. That’s why we chose to combine the best of both worlds—placing the YAML pipeline recipe editor and the pipeline preview canvas side by side. This is how the current version of Instill Core is designed, and we have a long list of UI/UX improvements planned to further enhance the experience.
Today, you can use Instill Core to build chatbots, plant phenotype analyzer, complex PDF parser, crawl websites, or even an advanced RAG system for AI agents’ tools. Wait… AI agent? Isn’t that yet another pedantic buzzword in this article? Well, at Instill AI, we view all AI-first applications and tasks as unstructured data ETL pipelines. Video 1 and Video 2 offer a glimpse into what this looks like in action.
Building pipelines with YAML recipes is fantastic. We love it. Our early adopters love it. But as passionate software product enthusiasts, we knew there had to be an even better way.
Chat-based Instill AI (2025)
The future is no longer ahead—it is now.
We’ve seen GitHub Copilot, Cursor, and Windsurf generating code for AI users, while Bolt.new and Replit are further enabling them to create full-stack software. Similarly, pipeline YAML recipes in Instill Core can now also be AI-generated, marking a new chapter in data ETL tooling and unlocking opportunities for non-technical AI users to harness the value of their data.
Building on this momentum, we are developing Instill AI—a chat-based multi-agent framework (yes, that’s the product name). Designed to help knowledge workers extract value from all types of data and automate repetitive tasks, Instill AI is built 100% on Instill Core, leveraging unstructured data ETL pipelines as agent tools. While Instill AI remains focused on unstructured data value exploitation, it will now make these capabilities accessible to all AI Users through chat-based automation.
Compared to a typical AI chat product customized from GPT (a.k.a. a GPT-wrapper), Instill AI empowers knowledge workers in the following key areas:
- Exploration: Gain a 360º perspective on knowledge discovery.
- Discovery: Dive deep into specific topics with precision.
- Analysis: Examine relationships, compare differences, and draw insights across multiple data points.
- Unstructured Data ETL: Process and extract valuable insights from large volumes of unstructured data, including documents, websites, images, videos, and audio.
- Faithfulness: Receive high-fidelity answers that you can trust.
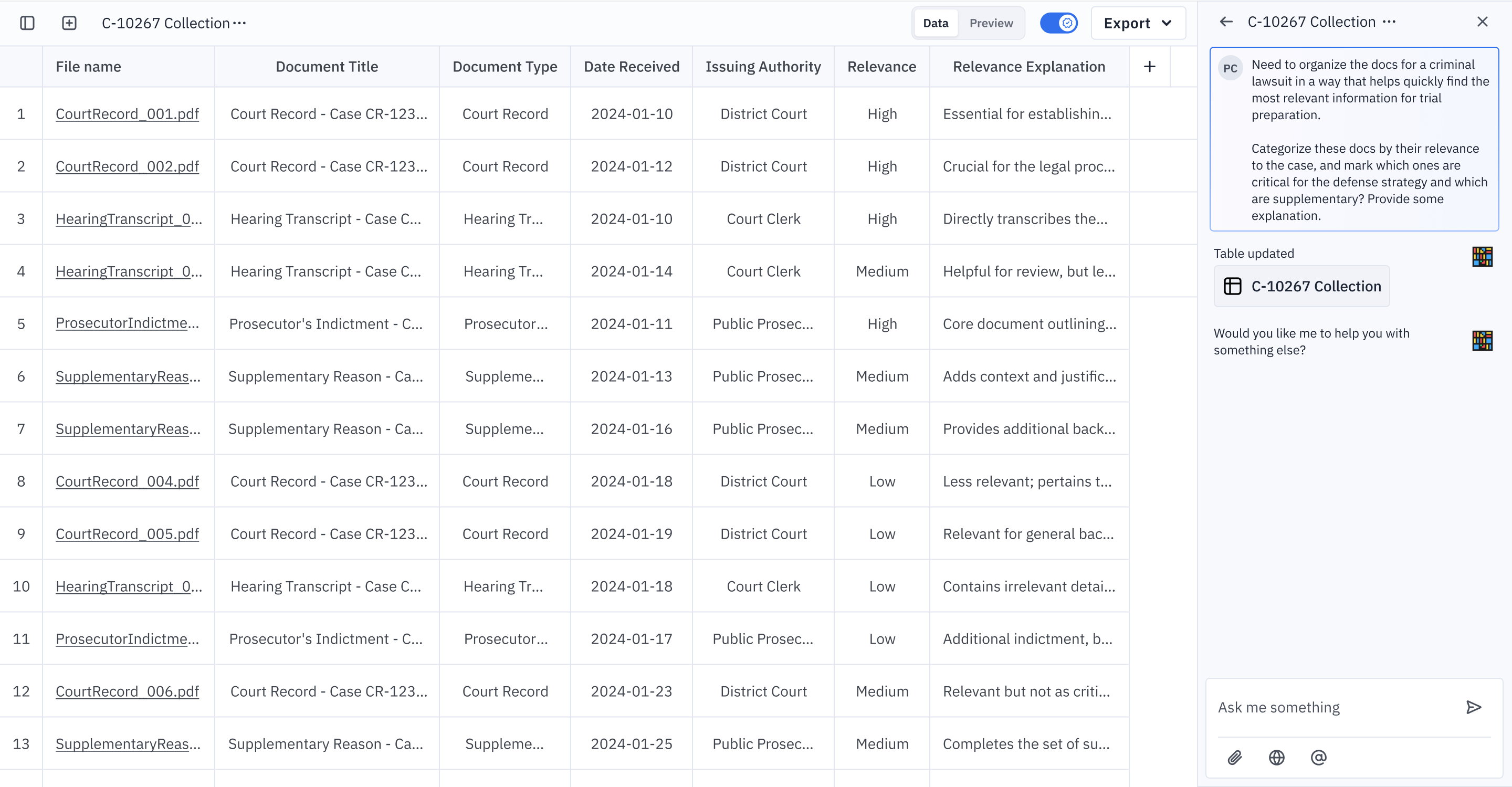
Think of Instill AI as an AI agent that cleans, processes, and organizes data, enabling you to streamline and optimize your knowledge workflow efficiently (See Figure 5).
We will soon sunset Instill Cloud, the fully managed cloud service for Instill Core, following the private launch of Instill AI in March. If you’d like early access to Instill AI while continuing to use Instill Core’s foundational features via the backend console, please sign up for the Instill AI waitlist and share your use cases for unstructured data ETL pipelines. We’ll reach out and grant access accordingly.
Looking forwards and onwards
This article is a reflection on my three-year journey of building AI products and where we’ve landed so far. I understand that everyone has different perspectives on software tooling and how AI products should evolve. That said, I am now firmly convinced that chat-based UI/UX is the most accessible and intuitive way for everyone to harness AI. However, the use of AI doesn’t have to be limited to chat, search, code completion or content generation, and data ETL doesn’t have to rely on drag-and-drop no-code UI or verbose DSLs—they can evolve together far beyond.
The biggest advantage of being a lean startup is speed. But no matter how fast we move, a wrong direction leads nowhere. We could have pursued a go-to-market strategy with the no-code pipeline builder or the low-code pipeline recipe for only AI Builders, but we chose not to. Instead, we bet on Generative AI’s versatility, evolving our product with it in parallel—not just because as a startup we can, but also because of who we are, what we’re capable of, and what the market truly demands. We can serve a bigger audience for all AI Users.
We’ve learned this lesson the hard way—from building a no-code solution to a low-code product for AI Builders, and now shifting our focus to a chat-based AI agent for knowledge workers. I hope you’ve found insights you need in our experiences. I envision a computer system that interprets any physical signal and intelligently responds to any language instruction. This vision is closer than ever to becoming reality, and I am thrilled to be part of this once-in-a-lifetime opportunity.
Glossary
Generative AI
- Generative AI encompasses models like Large Language Models (LLMs), Vision Language Models (VLMs), Large Multimodal Models (LMMs), Large Reasoning Models (LRMs), and diffusion models, enabling tasks such as text generation, code completion, image-to-text, image-to-image, text-to-speech (TTS), speech-to-text (STT), etc.
- LLMs, such as GPT-4o and DeepSeek-V3, are trained on extensive text datasets to produce human-like text.
- VLMs, such as OpenAI-o1, OpenAI-o3-mini, and LLaVA-CoT, are trained on a combination of text and image datasets to produce human-like text and images.
- LMMs integrate multiple data types, like text, images, videos, and audio, to enhance understanding and generation across modalities.
- LRMs focus on advanced reasoning capabilities, aiming to improve problem-solving and decision-making processes, such as OpenAI-o1, OpenAI-o3-mini, and DeepSeek-R1.
- Diffusion models, like DALL-E and Stable Diffusion, generate images by progressively refining random noise to match a given text prompt.
Traditional Data ETL vs. Unstructured Data ETL
- Data ETL (Extract, Transform, Load) is a data integration process that extracts data from various sources, transforms it to fit operational needs, and loads it into a target system, such as a data warehouse. It is also known as data washing, data wrangling, or data massaging.
- Unstructured data ETL involves extracting data from various unstructured sources (like text documents, images, or videos), transforming it into a structured format suitable for analysis, and loading it into a target system such as a data warehouse or database.
| Traditional Data ETL | Unstructured Data ETL | |
|---|---|---|
| Data Type | Structured data (e.g., tables, relational databases). | Unstructured data (e.g., text, images, videos, PDFs, logs). |
| Extract Sources | SQL databases, CSV files, spreadsheets. | Documents, emails, social media, multimedia, logs. |
| Transformation Process | Schema mapping, aggregations, data cleaning, indexing. | LLM, Embeddings, OCR (Optical Character Recognition). |
| Tools Used (generally) | Apache Spark, Informatica, Airflow, etc. | Instill Core, LangChain, Hugging Face, Unstructured.io, etc. |
| Loading Destination | Data warehouses (Snowflake, BigQuery, Redshift). | Vector databases (Pinecone, ChromaDB), document stores (Elasticsearch, MongoDB), blob storages (GCS, S3, MinIO) |
| End Use Case | BI dashboards, financial reports, analytics. | AI-powered search, RAG (Retrieval-Augmented Generation), chatbots, content analysis. |
AI Builders vs. AI Users
- AI Builders are the innovators who design, develop, and optimize AI-first products, leveraging skills in machine learning, software development, and data science to create AI-driven technologies. In contrast, AI Users are professionals who utilize these AI-first products to enhance productivity, applying AI in areas like automation, content creation, data analysis, and decision-making. While builders work with tools like PyTorch, TensorFlow, and Hugging Face to build AI solutions, users interact with AI-powered applications such as ChatGPT, GitHub Copilot, and AI-driven analytics tools to streamline their workflows. Please refer to the table below.
| AI Builders 👩🔧👨🏻🔧 | AI Users 👩💼👨🏻💼 | |
|---|---|---|
| Definition | People who design, develop, and build AI-first products. | People who use AI-first products to enhance their productivity. |
| Primary Goal | Create and optimize AI-driven technologies. | Leverage AI to improve efficiency and decision-making. |
| Key Activities | Developing machine learning models, fine-tuning LLMs, integrating AI APIs, building AI-powered applications. | Using AI for automation, content generation, data analysis, research, and communication. |
| Required Skills | AI/ML engineering, software development, data science, product management. | Domain expertise in their respective fields, ability to effectively interact with AI tools. |
| Examples | Engineers at OpenAI, Hugging Face, Google, or startups creating AI-driven apps. | Writers using ChatGPT, marketers leveraging AI analytics, coders using AI-assisted programming tools. |
| Tools Used | Instill Core, PyTorch, TensorFlow, Hugging Face, LangChain, OpenAI API. | Instill AI, ChatGPT, Midjourney, GitHub Copilot, AI-powered automation tools. |